In this post, we will survey data storage formats, and data management. The questions we will be asking are
- How and where the data is store
- Ways in which it is accessed
- Transformations it undergoes
Assumptions
We will only be looking at open source data formats. Our assumptions are:
- We are working with a distributed system. Data may be stored in a distributed fashion.
- The size of data is in hundreds of terabytes.
- Data is accessed by several consumers during developend lifecycle, for various purposes:
- Configuration
- Message passing
- Data ingestion
- Data analysis
- Machine learning model training
- Simulation
The use case we have in mind is data for robotics and self-driving cars. However, we won’t restrict the discussion to these domains. The data storage formats we are considering can apply to many other fields that deal with distributed computing and hundreds of terabytes of data.
Form follows function
There are many uses for data, and storage format is adapted to the function of the data.
- We make no endorsement of any single storage format!
- … We try to understand the function first
- … Each function has 2-3 storage format option that are appropriate
We will be talking about:
- Config & web file formats:
- JSON, YAML, XML
- Serialization file formats:
- Pickle, NPZ
- Protobuf, Thrift, AVRO
- Databases
- SQL (Relational) vs NoSQL (BigData)
- Row-based, columnar
- Columnar file formats
- Parquet, DeltaLake, ORC
- Data Lakehouse architecture
- Databricks, AWS SageMaker
- Deep Learning data loader
- TFRecord (file format)
- Petastorm (data loader library)
- Dvc (data repository)
JSon
JSon stands for JavaScript Store Object Notation. It has a lightweight syntax, and it is easy to understand by humans. Here is an example JSon file:
{
"employees": [
{
"firstName":"John",
"lastName":"Doe"
},
{
"firstName":"Anna",
"lastName":"Smith"
},
{
"firstName":"Peter",
"lastName":"Jones"
}
]
}
Readers familiar with JSon will immediately recognize that this defines an employees list, with each list element an array with two fiels, firstName and lastName.
Why is JSon popular?
- Contents is easy to ‘figure out’ without a schema
- Json is widely used in web and client/server applications. It allows client software to be developed independently of web server software.
What limitations does JSon have?
- It is schemaless.
- JSon is not size efficient.
- … And JSon does not allow comments.
Being schemaless is both an advantage, and a disadvantage of JSon. More precisely - users can define their own schema for JSon files, but they would have to make their own schema implementation, because JSon does not natively support a concept of schema.
YAML
The YAML format is…
- Used for configuration
- … Could be used for data serialization
- Created to solve problems of XML
- Simple to read & write by humans
Here is the same example contents expressed in YAML:
employees:
- firstName: John
lastName: Doe
- firstName: Anna
lastName: Smith
- firstName: Peter
lastName: Jones
# Some comment
As you can see, YAML allows comments. Indentation is used to express nested syntax. Basic format is an enumeration of key: value elements. List elements are enumerated using a - character.
Why is YAML popular?
- It is widely used for configuration files for dev/ops
What limitations does it have?
- It is schemaless
- Not size efficient
- When configs large and repetitive, it becomes difficult to read.
A typical difficulty is figuring out the indentation of YAML blocks when the file spans multiple screens that need to be paged-up and paged-down.
XML
- XML is often used when data is sent from a web server to a client.
- It is a Markup language. You can add attributes to entities.
- HTML was original language of Web. XML is an evolution of HTML.
- XML supports syntax enforcement through DTDs and Schemas
Here is our document expressed as XML:
<employees>
<person firstName=”John”
lastName=”Doe” />
<person firstName=”Anna”
lastName=”Smith” />
<person firstName=”Peter”
lastName=”Jones” />
</employees>
<!-- Some comment -->
<!-- DTD schema -->
<!DOCTYPE employees [
<!ELEMENT person (#PCDATA)>
<!ATTLIST person firstName CDATA #REQUIRED>
<!ATTLIST person lastName CDATA #REQUIRED>
]>
XML distinguishes between blocks (in our case, employees and person), and attributes (in our case, firstName and lastName).
The person block is empty and only has attributes. The employees block has no attributes, and has multiple person subblocks.
When is XML popular?
- When you want different renderings depending on style
- When you need strong schema support
- For a long time, XML was used to store configuration (until YAML came along)
Limitations of XML:
- Difficult to balance end bracket by humans
- Not size efficient
In robotics, XML is used by ROS (Robot OS), and by the Gazebo simulator.
Object Serialization
The setup for serialization is as follows:
- Assume we have an object with embedded pointers
- We want to pass it to another process
- One time
- Or, many times, repeatedly
- The process1 CPU could be big endian, while the process 2 CPU could be little endian

- … Or, you could save state to disk across process runs (This is more similar to sending it one time)
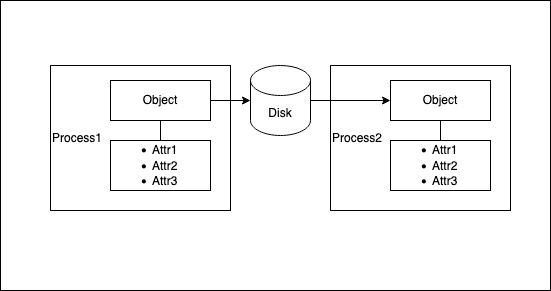
- … Or, you could do more complicated things:
- Save a set of instances of the same object into a database table, along with the object schema
- Convert an entire database table into a set of instances of the same object, creating the object schema dynamically
Pickle
- Used to serialize a python object
- Can save to disk, restore from disk
- Format is relatively compact
- And format is self-describing

Example:
# Save a dictionary into a pickle file.
import pickle
favorite_color = {"lion": "yellow", "kitty": "red"}
pickle.dump(favorite_color, open("save.pkl", "wb"))
# Load the dictionary back from the pickle file.
favorite_color1 = pickle.load(open("save.pkl", "rb"))
# favorite_color1 is now a clone of favorite_color
The pickle format is
- Only supported in Python
- Easy to use
- Mostly for saving/restoring objects to disk
- Not really for inter-process communication
- A bit inefficient
- Be careful when writing from one version of Python, and reading from a different version!
NPZ
- Available in the Python numpy module only
- It is similar to pickle, but for saving multiple objects
Example:
>>> x = np.arange(10)
>>> y = np.sin(x)
>>> outfile = TemporaryFile()
>>> np.savez(outfile, x=x, y=y)
>>> outfile.seek(0)
>>> npzfile = np.load(outfile)
>>> npzfile.files
['y', 'x']
>>> npzfile['x']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
References: 1
Protobuf
This is a serialization technology that has been open sourced by Google.
- It is language independent
- Both Process1, Process2 have a copy of the same object schema, and exchange only data.
- The schema is separate from serialized data. Here is an example schema:
//polyline.proto
syntax = "proto2";
message Point {
required int32 x = 1;
required int32 y = 2;
optional string label = 3;
}
message Line {
required Point start = 1;
required Point end = 2;
optional string label = 3;
}
message Polyline {
repeated Point point = 1;
optional string label = 2;
}
For example, to express the following Json object:
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
you would define the following protobuf schema:
// Protobuf Schema:
message Person {
required string userName = 1;
optional int64 favouriteNumber = 2;
repeated string interests = 3;
}
This image shows how a protobuf message is encoded:

Here are the pluses and minuses of protobufs:
- Efficient encoding
- Supports schema evolution … … But version changes can be difficult if not properly designed
Thrift
Thrift is similar to Protobuf, in that it allows serialization of objects. It was open sourced by Facebook, and is now an Apache project.
More than Protobuf, however, Thrift can be used to generate cross-language services. A .thrift file can be compiled into a service implemented in C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml, Delphi and other languages
To express the following Json object:
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
you would define the following Thrift schema:
// Thrift Schema:
struct Person {
1: required string userName,
2: optional i64 favouriteNumber,
3: optional list<string> interests
}
Thrift has two encoding protocols: binary, and compact. The binary scheme uses fixed length packing for numeric data types.

The compact encoding uses variable length packing, thus being very similar to the Protobuf encoding scheme.

References: 1
AVRO
- Serialization language similar to protobuf and thrift
- But does not allow generation of cross-language services
- AVRO from Apache (Protobuf from Google, Thrift from Facebook)
- Started as a subproject of Hadoop, because Thrift did not solve all use cases necessary in that project.
- Supports schema evolution
- You can actually use separate writer and reader schemas with Avro. The parser can use resolution rules to translate data from the writer schema into the reader schema.
- … But version changes can be difficult
Data (in JSON):
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
AVRO Schema:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
This is how AVRO encoding looks like:

AVRO pluses and minuses:
- In Protobuf, every field in a record is tagged, whereas in AVRO, the entire record, file or network connection is tagged with a schema version.
Remote Procedure Calls (RPC) with Protobuf, Thrift, AVRO
Thrift, AVRO have RPC support built-in. gRPC extends Protobuf for RPC.
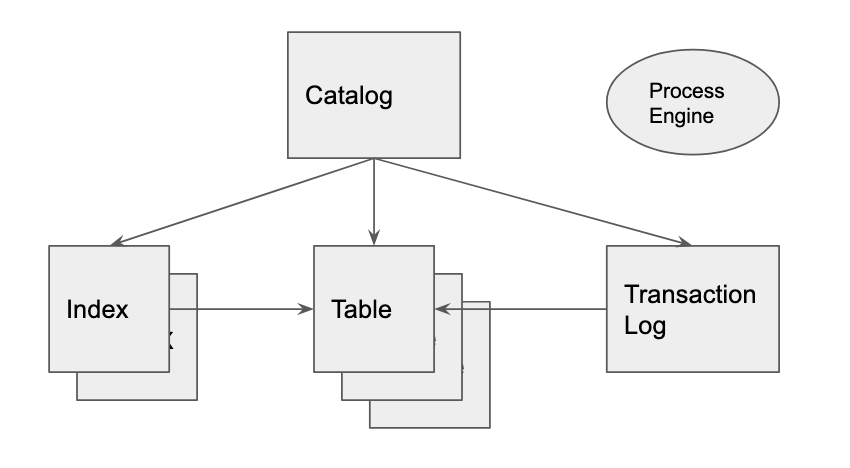
The Relational Database Architecture
- Tables stored in multiple files
- Indices for faster table lookup
- Transaction Log, for atomic transactions
- Catalog
- Process Engine (read,write,log,checkpoint)