Summary of Yann LeCun’s talk at Northeastern:
- What is a model for AGI
- Why a hierarchical planning is needed
- How hierarchical learned planning has not been solved
- Why energy models are necessary, in this context
- How to use energy models and joint embeddings for this
- Example of unsupervised model for predicting outcome in video - implementing some form of the hierarchical planner
About LLMs:
- He is critical of auto-regressive Large Language Models (LLMs), saying that without further improvements, the vast parameters and computational power will ultimately lead to failure.
- Key here is
auto-regressive. Putting a planner on top of LLMs, or a chain of thought, etc - these can solve the problem
- Key here is
- He says auto-regressive LLMs are prone to numerous irreparable and uncontrollable hallucination errors, lacking reasoning and planning abilities.
- While auto-regressive LLMs they may approximate certain aspects of the human brain’s Broca/Wernicke language areas, they fall far short of true human intelligence.
In terms of future AI development, LeCun puts forth several propositions.
- He predicts that autoregressive LLM-based ChatGPT will fade into obscurity within five years.
- Other architectures will replace them
- He emphasizes the necessity for future tech giants to prioritize the creation of open-source infrastructure for the next generation of artificial intelligence. This approach would eliminate the need for every company to compete solely based on computational power and parameter quantity.
- LeCun highlights the limitations of current AI systems, emphasizing their struggles with autonomous driving and the complexity of pharmaceutical engineering.
- As a result, AI applications remain confined to specific domains.
LeCun pointed out the significant risks associated with utilizing AI to read and write biomedical literature. LLMs can deceive laypeople by appearing knowledgeable, and even experts can detect fundamental misconceptions yet still be misled.
For professionals dedicated to fostering the healthy development of Artificial General Intelligence (AGI), LeCun offers some advice.
- He encourages them to deepen their understanding of the biological and neuroscientific foundations of animal and human learning, reasoning, and planning.
- He suggests gaining knowledge in statistical physics and quantum physics, thus establishing a robust foundation in science and technology beyond mere programming skills, which he considers to be low-level repetitive tasks that could potentially be replaced.
- He stresses the importance of cultivating critical and independent thinking to avoid succumbing to herd mentality.
- LeCun laments the numerous short-lived trends he has witnessed in the AI field, leaving behind nothing but confusion.
In more detail:
- He compares supervised with unsupervised models
- Explains BERT
- Explains text-based generative models
- Trained to predict next token (word or subword)
- Have to train on 1-2 trillions of tokens, for the biggest models
- With 1B to 500B parameters
- Once trained, pass in a prompt, and use recursively to predict next, and next token. This is called auto-regressive prediction.
- That’s how all big LLMs work BlenderBot, Galactica, LLaMa(Meta), Alpaca(Stanford), LaMDA/Bard(Google), Chinchilla(DeepMind), ChatGPT(OpenAI), GPT-4…
- Amazing performance, stupid mistakes.
- Factual errors, logical errors, inconsistencies, limited reasoning abilities.
- Gullible. You can persuade them that 2+2=5.
- Can hallucinate.
- Not good for reasoning, planning, arithmetic
- Can use them for writing assistance, first draft generation, code generation.
- Software engineerig will be revolutionized.

- No knowledge of underlying reality.
- No common sense, no ability to plan answer (not the auto-regressive LLMs themselves)
- Auto-regressive LLMs cannot be made factual, non-toxic.
- Auto-regressive process diverges from correct answer exponentially
- Not fixable with current architecture.
- His bold prediction is that the shelf life of auto-regressive LLMs is very short.
- 5 years from now, no one in their right mind will use them
- Will be replaced by things that are better


- How could machines learn like animals and humans? Babies under 14 month gradually understand: (per Emmanuel Dupoux)
- Actions: face tracking, biological motion, rational goal-directed actions
- Physics: stability support, understanding gravity, inertia, conservation of motion
- Objects: object permanence, solidity, rigidity, natural kind categories, shape, consistency
- How can teenagers learn to drive with 20h of practice?
- We’re missing something big
-
The path to general AI, to self driving cars, is not to make LLMs bigger.
- How do babies learn how the world works?
- Largely by observation, with little interaction (initially)
- They accummulate enormous amounts of background knowledge
- About the structure of the world, like intuitive physics
- Perhaps common sense emerges from this knowledge
- General intelligence will probably emerge from the ability of machines to learn how the world works by observation, the way babies and animals do it
Three challenges for AI over the next decade or so:
- Learning representations of the world. Learn to predict the world.
- Self-supervised learning
- Learning dependencies
- Ability to fill in the blank
- …But in a non task-specific way
- Learning predictive models for planning and control
- Learning to reason.
- Should work like Daniel Kahneman’s System 1 (subconscious), System 2 (conscious) thinking
- Reasoning and planning should be a form of energy minimization
- Learning to plan complex action sequences
- Decomposing them into simpler ones

LeCun describes his paper from last year, A Path Towards Autonomous Machine Intelligence, posted on openreview.net.
- The technical talk for it is From Machine Learning to Autonomous Intelligence (2022) (Berkeley)
- It is based on a cognitive architecture
- Configurator/orchestrator
- Perception
- World Model
- Cost
- Cost function is a measure of disconfort of the agent
- Basal ganglia has things like that - tells you when you’re hungry, for example, or you’re hurting
- Nature tells you that you’re hungry, but not how to feed yourself. You have to plan that.
- Imagine this is a robot. The battery level is the cost fuction. The battery starts to get drained.
- Robot has to plan to attach itself to a socket, to recharge. That will eventually minimize the cost function
- Actor
- Short-term memory
Here is a ‘system 1’ implementation of this:

- The encoder (=perception system, in pink) makes an estimation of the world
- The state of the world runs through a policy network (in yellow)
- That produces an action
- The action goes into the world
LLMs are like this. They are ‘System 1’. No reasoning necessary.
Here’s a ‘system 2’ implementation:
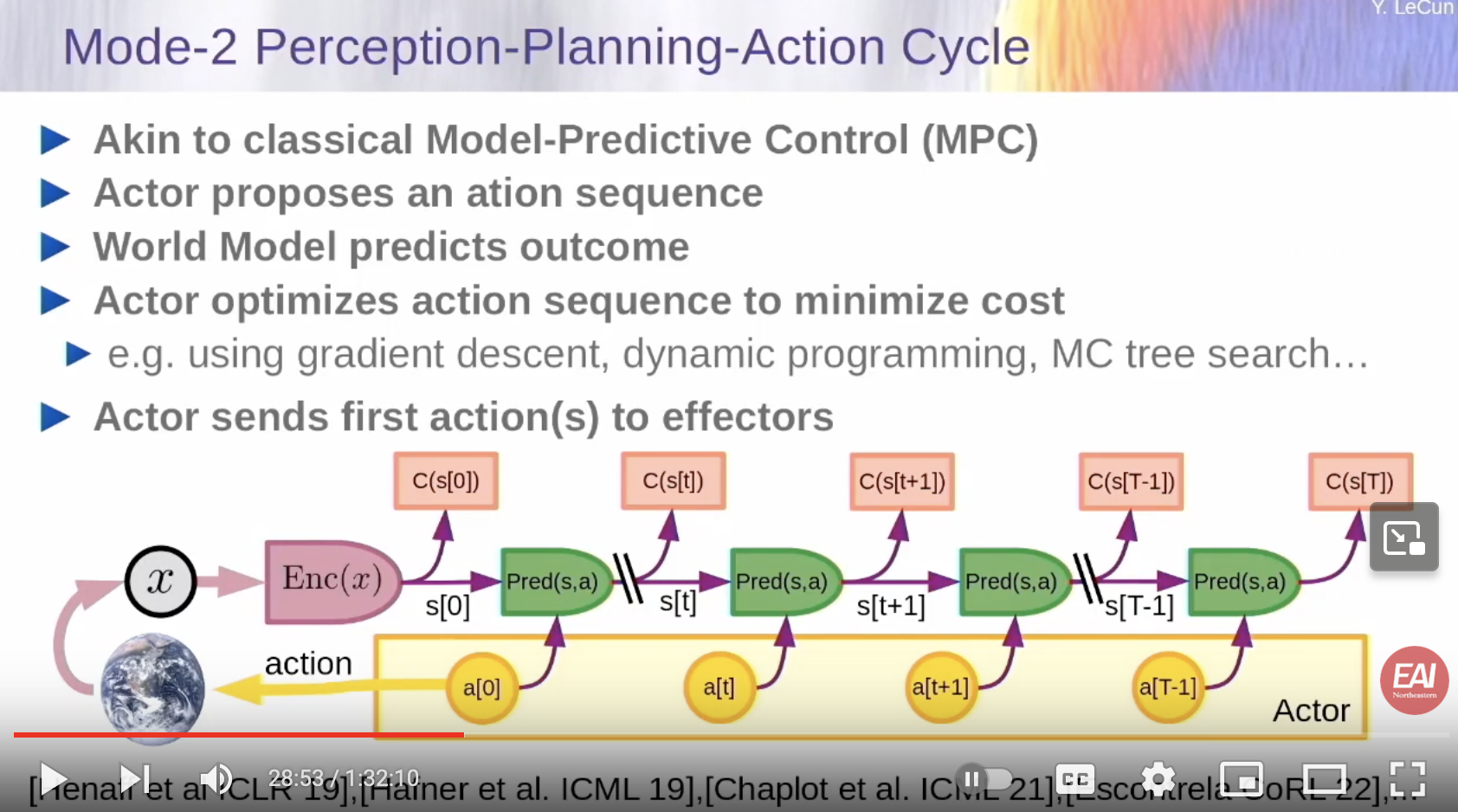
- Similar to Model-Predictive Control (MPC)
- The world model is the green module
- The different instances of the green module are the state of the systems at differnt time steps
- Think of it like a recurrent net that you unfolded
- What the world model is supposed to predict: Given a representation of the state of the world at time
t, and an imagined action at timet- what is going to be the predicted state of the world at timet+1 - I can imagine the sequence of steps I might take. I can imagine the sequence of actions.
- I can project my cost, at each time
t, and measure if my cost is going to be minimized by this action sequence. - What I should do - run an optimization procedure that will search through this sequence of actions and minimizes the cost, given the prediction given to me by the world model
- This type of planning is very classic in optimal control
- Called Model-Predictive Control
- In classical control, the model is not learned. It’s just hand crafted.
- Here, we are thinking of a situation where the world model is learned
- Learned by, for example, watching the world go by, by video
- Also, by observing actions in the world, and seeing the effects
Ultimately, we want hierarchical version of this. (This is at the 30m mark in the clip.)

- If you want the system to plan complex actions, we can’t plan it at the lowest level
- For example, if I want to plan to go from here to NYC, I would have to basically plan every millisecond exactly what muscle actions I should take.
- That’s impossible to do just that. You can’t plan the entire trip to NYC like this.
- Partly b/c you don’t have a perfect model of the environment
- You don’t know, once you go out of the room, what is going to be in the way, and how you’ll go around that
- So you can’t completely plan in advance.
- So I have to plan hierarchically.
- The cost function at the top is the distance to NYC
- The 1st thing I have to do is - go to the train station an catch a train
- The top predictors say - if I catch a taxi, I can go to the train station. If I go to the train station, I can catch the train.
- These intermediary states are the
zvariables here. - They define a cost function for the next level down.
- The lower level is - how do I catch a taxi to go to the train station
- No, this is Boston, so I need to catch an Uber or something
- So I go on the street
z1[0], and call an Uberz1[1]- (There’s a typo on this slide)
- How do I go on the street? There’s going to be lower levels. I have to go out of this building.
- How do I get out of this building? I have to get out of the door.
- How do I get out of the door? I have to put one leg in front of the other. Go around obstacles. All the way down to millisecond - motion control for very short period. Which is replanned as we go.
- No AI system today can do any of this!
- This is completely virgin territory!
- A lot of people worked on hierarchical planning, but in situations when the representations at every level are hard wired - known in advance. Predetermined.
- This is the equivalent of a vision system where the features at every level are hard wired.
- There’s no system today that can learn hierarchical representations for action plans.
- So that’s a big challenge.

- A lot of people are talking today about AI systems that are not steerable, difficult to control, perhaps toxic
- The system I describe cannot produce output that does not minimize the cost
- Having a system like this is guaranteed to be safe. You program the safety in the cost.
-
LeCun does not think the problem of making AI safe is such a huge problem
- The cost is a sum of intrinsic cost IC (immutable cost module, hard wired), and trainable cost TC (predicting the future IC - equivalent to critic in RL).
- The TC implements subgoals

How do we build the world model?
- How do we build it to predict the world
- World is not always predictable
- Probabilistic models intractable in continuous domain
- Generative models must predict every detail of the world
- LeCun’s solution: Joint embedding predictive architecture
- This is the most important slide of the talk

- The left is a generative network - for example, you run the model for a while, train it to predict
y, then predicty - Examples: variational autoencoder, masked autoencoders
- All NLP systems, including LLMs, are of this type
- They’re generative models
But you don’t want to predict every detail of the world!
- That would be easy if it’s text, because text is discrete
- Predicting probabilities for next word over all words in the dictionary is possible
- Can’t do this over every frame in a video clip
- Cannot possibly represent a distribution over all video frames
- The reason we have LLMs that work so well is - text is easy. Language is simple.
- It’s also processed in the brain by two tiny areas - the Wernicke area, for understanding, and the Broca area, for production [there’s two other small areas, Angular Gyrus and Superior Temporal Gyrus, says ChatGPT]
- What about the prefrontal cortex, where we think?
- LeCun proposes replacing the generative architecture with a joint embedding architecture
- The purpos of
Enc(y)is to drop details aboutythat are not essential - If I shoot a video of the room here, and pan in the camera, it would be able to predict there are multiple people, and where they sit - but could not predict your age, gender, hairstyle, details like that
- Issue with this model: if you train the system with
xa piece of video, andya following piece of video, it collapses - How do we prevent collapse?
- There are three flavors

- How do you train them?

- Have to explain energy model
- When using joint embedding, the proabilistic model paradigm goes out the window
- What is an energy based model?
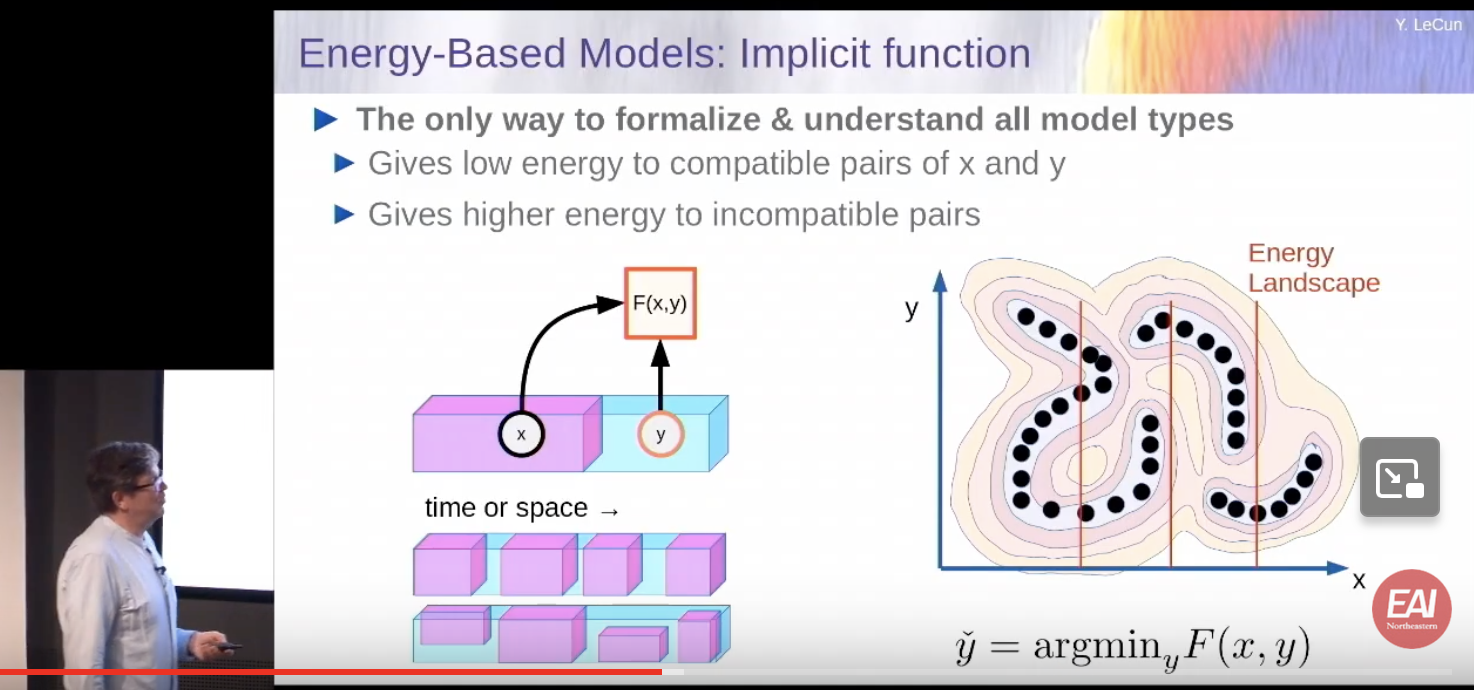
- Energy function
F(x, y)is minimized whenycorresponds tox. - This gives
yas implicit function - How do you train them?

- Use contrastive method, regularized method


I’ll skip some details from his presentation. He goes through 4-5 slides rather quick.
Then he says - the reason to do JEPA is that it implements a world model, and multi-scale predictions

Early experiments with video, trying to predict what’s next:

He says it’s working pretty well (but does not provide details)

Summary slide at the end:

Andrei’s take:
LeCun is Chief Scientist of Meta, and, from that position, things look different than, say, from OpenAI, or Google.
Meta is similar to OpenAI and Google in that it has a strong research-based data science group. But it is different in that it is focused on social media.
Meta does not provide cloud services like AWS and GCP, though it has a very sophisticated cloud as a back end for its multi-billion-strong user base.
Nor does Meta provide search or chatbot-based services to end users.
Meta basically sits on LLM and camera-based computer vision technology its engineers are perfectly capable to develop - but it’s too preoccupied with social media competition from the likes of Tik-Tok to monetize on its internal LLM and computer vision research.
That explains LeCun’s position, a bit. It’s not like he’s against LLMs and chat agents - or that he’s dismissive of it.
What he’s saying, rather, is that Meta will keep open sourcing its LLM tech stack, undercutting OpenAI and Google.
So, long term, LeCun says, we should expect LLMs and computer vision foundational algos to be commoditized, as a result of Meta’s corporate strategy. If Meta had the bandwidth to build a business around all this research it is doing, things would play out differently.
For more context on LeCun - his preprint A Path Towards Autonomous Machine Intelligence has a lot of stuff applicable to language models and langchain type applications.
And he’s teaching an NYU class on energy models and joint embeddings.
The flavor of his work seems directed from challenges at Meta - where they sit on large amounts of text and vision data, and are looking to build self-supervised value out of that.
LeCun is also very theoretically minded. I think he might have a background in abstract math, or physics. He is a brilliant mind.